Open-vocabulary Queryable Scene Representations for Real World
Planning
 Everyday Robots
Everyday Robots
 Robotics at Google
Robotics at Google
Abstract
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods.
Demo Video
NLMap + SayCan
NLMap can be combined with LLM planners to significantly augment the
capability of real robot operation. We connect NLMap with SayCan, a
recent work that uses LLM planners to let robots plan and execute
according to natural language instructions. NLMap free SayCan from a
fixed, hard-coded set of objects, locations, or executable options.
SayCan also fails to plan with global context awareness which is
addressed by NLMap. With NLMap, SayCan can now perform a great number
of previously unachievable tasks.
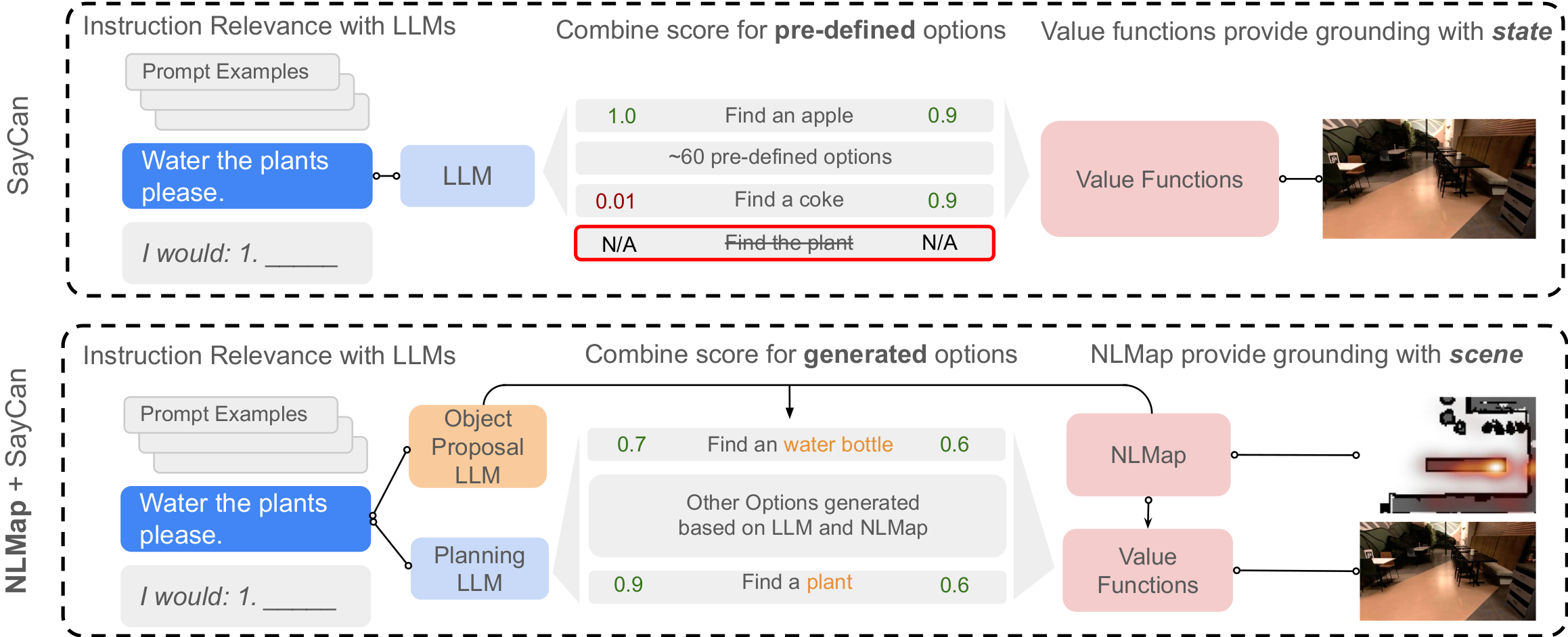
As shown in the diagram above, SayCan combines LLM scores and
affordance to plan a sequence of steps to accomplish specified by
instructions. SayCan relied on a fixed list of object names and
locations so would fail on instructions like "Water the plant"
beucase plant is not in its pre-defined list. NLMap, on the other
hand, actively proposes involved objects, options and query the
scene representation for object locations. It, therefore can perform
the task "Water the plant".
Method
We first let the robot explore the scene and gather observations. A class-agnostic region proposal network proposes region of interest and encode them into Visual Language Model embeddings. The embeddings and object bounding boxes are aggregated by a multi-view fusion algorithm to create a representation that will be later queried with natural language inputs.

When human gives an instruction, a large language model parses the instruction into a list of related objects. We then query the scene representation for availability and locations of these objects. Executable options are generated based on what’s found. Finally, the robot plan and accomplishes the task based on the instruction and the found objects.

Code
While the code for NLMap is Google proprietary, some community members reimplemented NLMap for their own projects using a Boston dynamics spot robot. You can find their reimplementation here. We don't officially support this code and verify its reproducability, but it is a good starting point.